Methodology
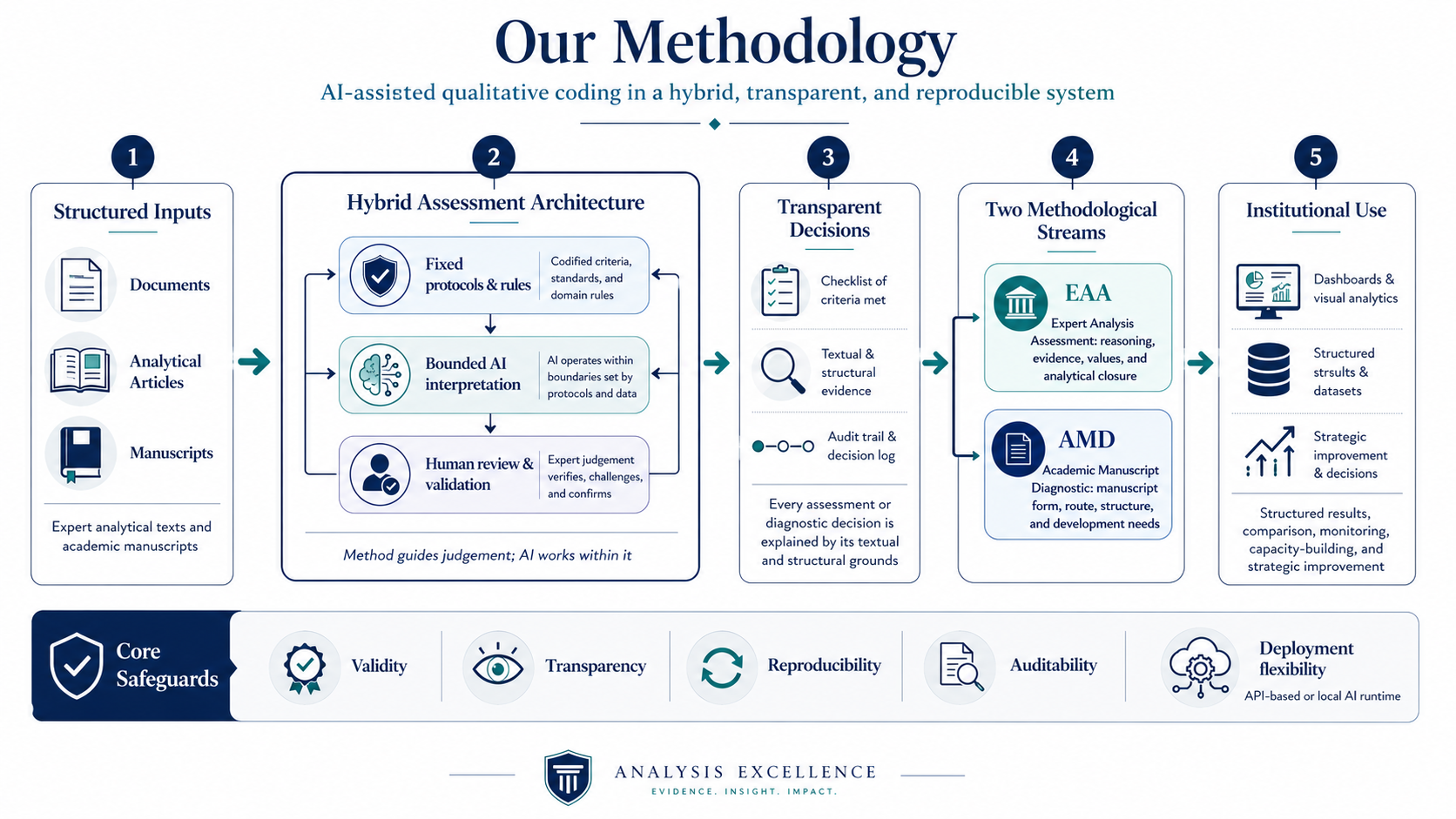
Our methodology is built around AI-assisted qualitative coding, but not generic AI automation. We do not simply hand texts to an AI model and ask for a judgement. Instead, AI-supported interpretation is embedded in a hybrid methodological system: fixed protocols, structured decision sequences, permitted labels, threshold tests, audit fields, validation routines, anchors, recalibration, and human review. The purpose is to convert complex qualitative judgement into structured, inspectable, and reproducible evidence.
The system is hybrid by design. Human methodological design defines the conceptual framework, the rules, the permissible outputs, the sequence of decisions, and the standards of review. AI-supported interpretation operates inside that framework. Software implementation then stores the results as structured data, records audit trails, enables filtering and comparison, and supports long-term monitoring. The AI is therefore not a substitute for method; it is an interpretive component inside a controlled methodological architecture.
Transparency is central to the approach. Every AI-supported assessment or diagnostic decision is expected to be explainable. The system does not only return a label, score, route, category, or review flag; it records why that output was reached, which textual or structural grounds supported it, which alternatives were considered, and which boundary checks were applied. This makes assessment and diagnosis transparent rather than opaque.
The methodology supports two separate assessment streams. Expert Analysis Assessment applies AI-assisted qualitative coding to professional analytical texts, including think-tank publications, policy papers, risk analysis, strategic commentary, consultancy outputs, and analytical magazines. It is conclusion-anchored: each text is decomposed into opening claim, developed reasoning, and final analytical closure, before Reasoning Autonomy, Axiology Autonomy, argumentative category, substantive type, evidence, uncertainty, and confidence are assessed.
Academic Manuscript Diagnostic applies AI-assisted qualitative diagnosis to academic manuscripts. It does not use the EAA RA/AA architecture. It has its own manuscript ontology, question-routing logic, denominator profiles, structured results, audit log, anchor ecology, recalibration logic, and reproducibility checks. AMD classifies manuscript form, knowledge-production mode, and review route before scoring, so that conceptual, review-synthesis, empirically informed, embedded-design, and full empirical manuscripts are assessed according to the route they actually justify.
Both streams can operate through external AI-provider access or through a configured local AI environment. This provider flexibility does not change the methodology: the same protocols, labels, thresholds, validation checks, audit expectations, and human-review requirements apply whether the model is accessed through an API or locally. The result is not black-box AI judgement, but a structured system for making analytical and scholarly assessment more valid, transparent, reproducible, auditable, and institutionally useful. The current app architecture supports both external-provider and local-model use, including LM Studio-style local configuration.
-
AI is used because the relevant judgements require close reading across many texts, consistent attention to structure, and repeated application of complex criteria. Without software support, these assessments are difficult to scale, compare, and audit. The role of AI is to assist the reading and classification process, while the methodology determines what may count as a valid assessment.
-
The system restricts the AI through fixed concepts, permitted labels, staged prompts, output schemas, threshold rules, and validation checks. It cannot legitimately create its own categories, invent a new scoring logic, or replace the protocol with a general impression. A result is useful only when it can be traced back to the relevant decision path.
-
Each major judgement is accompanied by an explanation of the grounds on which it was made. The system records the textual or structural basis for a classification, the relevant alternatives, and the reason why one interpretation was selected over another. This is especially important for boundary cases, where a small difference in interpretation can change the final result.
-
EAA assesses expert analytical texts by asking how the argument develops, how the conclusion is reached, and how reasoning, values, evidence, and explanatory object shape the final analytical closure. AMD assesses manuscripts by asking what kind of scholarly object the text is, which review route it requires, how its sections function, and where revision would most improve manuscript quality.
-
The purpose is not only to produce feedback on one text. Structured results allow organisations to see patterns across outputs: repeated weaknesses, recurring strengths, unstable thresholds, common manuscript problems, variation across teams or authors, and changes over time. This turns individual assessment into institutional learning.
-
Reproducibility does not mean that every sentence of an AI-generated explanation will always be identical. It means that the structured result should remain stable where the same text is assessed under the same method: the same route, category, score logic, confidence position, review flag, or diagnostic pattern should be recoverable and auditable.
-
Running the system with a local AI model can be useful for institutions with stricter data-governance or operational preferences. It changes the deployment environment, not the method. The same protocols, checks, fields, and review expectations remain in force whether the system is connected to an external provider or a local model.
-
Human review is most important where results are close to a boundary, where confidence is lower, where the system flags contradiction or drift, or where an institution intends to rely on results for training, publication strategy, or quality assurance. The software structures the judgement; it does not remove responsibility for interpreting and using it.